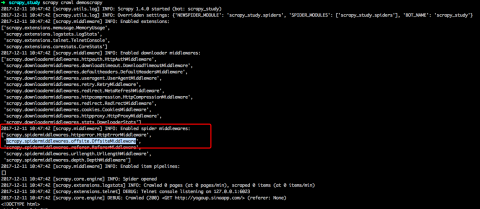
这是因为启用了allowed_domains设置的缘故。allowed_domains用于设置过滤爬取的域名,在插件OffsiteMiddleware启用的情况下(默认是启用的),不在此允许范围内的域名就会被过滤,因而不会进行爬取。但对于start_urls里的起始爬取页面,它不过滤,仅过滤起始爬取页面以外的页面。是否因过滤引起可检查允许scrapy crawl时打印的日志,如下图所示:
要解决此问题,可以有两种方法:
1)allowed_domains = ['examplesite.com']在爬虫类设置allowed_domains允许该网站主域名、或相关子域名范围内的所有页面的爬取
2)Request(urlparse.urljoin(response.url, url), dont_filter=True)中指定参数dont_filter,以确保不进行过滤。