groupby可以根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas数据集对象,对其进行切片、切块、摘要等操作,例如,计算分组摘要统计:计数、平均值、标准差,或用户自定义函数。此外,还可以对DataFrame对象的列应用各种函数,包括应用组内转换或其他运算,如:规格化、线性回归、排名或选取子集等、计算透视表或交叉表、执行分位数分析等。
一、groupby方法定义
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
by : 接收映射、函数、标签或标签列表;用于确定聚合的组。
axis : 接收 0/1;用于表示沿行(0)或列(1)分割。
level : 接收int、级别名称或序列,默认为None;如果轴是一个多索引(层次化),则按一个或多个特定级别分组。
as_index :接收布尔值,默认Ture;Ture则返回以组标签为索引的对象,False则不以组标签为索引。
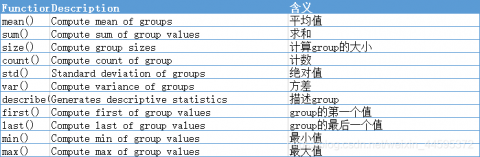
groupby的聚合函数:
二、简单示例
import pandas as pd
df = pd.DataFrame({'Gender' : ['男', '女', '男', '男', '男', '男', '女', '女', '女'],
'name' : ['周杰伦', '蔡依林', '林俊杰', '周杰伦', '林俊杰', '周杰伦', '田馥甄', '蔡依林', '田馥甄'],
'income' : [4.5, 2.9, 3.8, 3.7, 4.0, 4.1, 1.9, 4.1, 3.2],
'expenditure' : [1.5, 1.9, 2.8, 1.7, 4.1, 2.5, 1.1, 3.4, 1.2]
})
df
Out[12]:
Gender name income expenditure
0 男 周杰伦 4.5 1.5
1 女 蔡依林 2.9 1.9
2 男 林俊杰 3.8 2.8
3 男 周杰伦 3.7 1.7
4 男 林俊杰 4.0 4.1
5 男 周杰伦 4.1 2.5
6 女 田馥甄 1.9 1.1
7 女 蔡依林 4.1 3.4
8 女 田馥甄 3.2 1.2
#根据其中一列分组
df_expenditure_mean = df.groupby(['Gender']).mean()
df_expenditure_mean
Out[14]:
income expenditure
Gender
女 3.025 1.90
男 4.020 2.52三、计算平均值
用法描述:
1. 用groupby()对需要分类连接的属性进行分组。
2. 用mean()函数计算列的平均值。
备注:示例如上,groupby()生成的是一个GroupBy对象,它实际上还没有进行任何计算,只是含有一些有关分组键df['Gender']的中间数据而已,然后我们可以调用mean方法来计算分组平均值,其索引为key1列中的唯一值。在执行df.groupby(['Gender']).mean()时,结果中没有name列。这是因为df['name']不是数值数据,所以被从结果中排除了。默认情况下,所有数值列都会被聚合,虽然有时可能会被过滤为一个子集。
四、连接来自多行的字符串
方法描述:
1. 用groupby()对需要分类连接的属性进行分组。
2. 用transform()对值要连接的列值进行转换,用join()函数连接字符串,并使用lambda语句转换该列的值。
dfNames = df dfNames.loc[:,'name'] = dfNames.groupby(['Gender'])['name'].transform(lambda x : ' '.join(x)) dfNames = dfNames.drop_duplicates() dfNames Out[29]: Gender name 0 男 周杰伦 林俊杰 周杰伦 林俊杰 周杰伦 1 女 蔡依林 田馥甄 蔡依林 田馥甄
备注:该方法只能应用于仅包含分组列和要连接的字符串列,不能有其它有差异化数据的列,否则去重会失败。
五、依据多列进行分组
方法描述:
1. 用groupby()对需要分类的多个属性列进行分组,参数为列名数组。
2. 用mean()函数计算列的平均值。
df.groupby(['Gender', 'name']).mean()
Out[31]:
income expenditure
Gender name
女 田馥甄 2.55 1.15
蔡依林 3.50 2.65
男 周杰伦 4.10 1.90
林俊杰 3.90 3.45备注:该方法产生的结果的索引是Gender 和name构成的元组,虽然是 DataFrame 的格式,但是若需要与其他表匹配的时候,这个格式就有些麻烦了。匹配数据时,我们需要的数据格式是:列名都在第一行,数据行中也不能有 Gender 列这样的合并单元格。因此,我们需要做一些调整,将 as_index 改为 False ,默认是 Ture 。
df.groupby(['Gender', 'name'], as_index=False).mean() Out[32]: Gender name income expenditure 0 女 田馥甄 2.55 1.15 1 女 蔡依林 3.50 2.65 2 男 周杰伦 4.10 1.90 3 男 林俊杰 3.90 3.45
六、对分组进行简单的数值运算
方法描述:
1. 用groupby()对需要分类的一个或多个属性列进行分组,参数为列名数组。
2. 用apply()函数计算列的分组的某种运算。
df_apply = df.groupby(['Gender', 'name'], as_index=False).apply(lambda x: sum(x['income']-x['expenditure'])/sum(x['income'])) df_apply = pd.DataFrame(df_apply,columns=['存钱占比'])#转化成dataframe格式 df_apply_index = df_apply.reset_index() df_apply_index Out[37]: Gender name 存钱占比 0 女 田馥甄 0.549020 1 女 蔡依林 0.242857 2 男 周杰伦 0.536585 3 男 林俊杰 0.115385
七、获取分组的统计信息
1.用groupby()对需要分类的一个或多个属性列进行分组,参数为列名数组。
2.用agg函数,参数为各统计函数(apply several aggregation methods)
df.groupby(['Gender', 'name']).agg(['mean', 'count'])
Out[38]:
income expenditure
mean count mean count
Gender name
女 田馥甄 2.55 2 1.15 2
蔡依林 3.50 2 2.65 2
男 周杰伦 4.10 3 1.90 3
林俊杰 3.90 2 3.45 2
df1=df.groupby(['Gender', 'name']).agg(['describe'])
df1['income']['describe']
Out[44]:
count mean std min 25% 50% 75% max
Gender name
女 田馥甄 2.0 2.55 0.919239 1.9 2.225 2.55 2.875 3.2
蔡依林 2.0 3.50 0.848528 2.9 3.200 3.50 3.800 4.1
男 周杰伦 3.0 4.10 0.400000 3.7 3.900 4.10 4.300 4.5
林俊杰 2.0 3.90 0.141421 3.8 3.850 3.90 3.950 4.0八、对分组进行迭代
for (Gender, name), group in df.groupby(['Gender', 'name']):
print(Gender, name)
print(group)
女 田馥甄
Gender name income expenditure
6 女 田馥甄 1.9 1.1
8 女 田馥甄 3.2 1.2
女 蔡依林
Gender name income expenditure
1 女 蔡依林 2.9 1.9
7 女 蔡依林 4.1 3.4
男 周杰伦
Gender name income expenditure
0 男 周杰伦 4.5 1.5
3 男 周杰伦 3.7 1.7
5 男 周杰伦 4.1 2.5
男 林俊杰
Gender name income expenditure
2 男 林俊杰 3.8 2.8
4 男 林俊杰 4.0 4.1
著作权归作者所有。商业转载请联系本站作者获得授权,非商业转载请注明出处 ZZKOOK。
评论
谢谢ZZKOOK分享
希望能更深入,do 下钻 while 1