可以通过nohup工具,具体如下:noh... 可以通过nohup工具,具体如下: nohup scrapy crawl gen -o sz.csv &nohup和&之间是运行程序的指令。运行该指令够会有如下输出信息: nohup: ignoring input and appending output to `nohup.out' 该信息指明程序的输出存储在nohup.out中。
解决:Centos7安装Scrapy报错汇总与方法详解 使用scrapy爬虫的小伙伴可能有不少希望在云服务器上运行自己的爬虫程序,正如ZZKOOK一样,云服务器上设置好定时任务scrapy爬虫centos7疑难杂症
Ubuntu中安装EPDFree的替换方法 EPDFree是Enthought(https://www.enthought.com/)面向科学计算推出的pythonpythonpandasEPDFree
这是因为CRAN中存储的Ubuntu包需... 这是因为CRAN中存储的Ubuntu包需要通过密钥51716619E084DAB9进行签名验证。 因此需要运行以下命令添加密钥到ubuntu系统: $ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 51716619E084DAB9
改用root权限的sudo命令,如下:s... 改用root权限的sudo命令,如下: sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 51716619E084DAB9
检查scrapy工程目录下的geckod... 检查scrapy工程目录下的geckodriver.log日志,如果内容如下: Error: GDK_BACKEND does not match available displays 或 Error: no DISPLAY environment variable specified 表示没有可供显示的环境,因为是在命令行模式下(无头模式)试图启动firefox。此时需要为selenium的webdriver.Firefox设置其选项,如下: from selenium import webdriver
要解决此问题,可以有两种方法:1)all... 要解决此问题,可以有两种方法: 1)allowed_domains = ['examplesite.com']在爬虫类设置allowed_domains允许该网站主域名、或相关子域名范围内的所有页面的爬取 2)Request(urlparse.urljoin(response.url, url), dont_filter=True)中指定参数dont_filter,以确保不进行过滤。
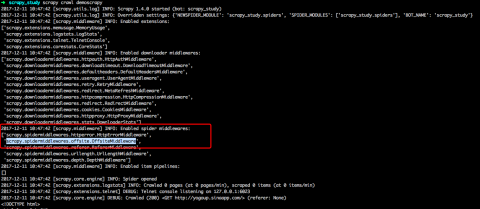
这是因为启用了allowed_domai... 这是因为启用了allowed_domains设置的缘故。allowed_domains用于设置过滤爬取的域名,在插件OffsiteMiddleware启用的情况下(默认是启用的),不在此允许范围内的域名就会被过滤,因而不会进行爬取。但对于start_urls里的起始爬取页面,它不过滤,仅过滤起始爬取页面以外的页面。是否因过滤引起可检查允许scrapy crawl时打印的日志,如下图所示:
xshell及其他终端连接linux时中... xshell及其他终端连接linux时中文乱码的原因一般有三种: (1)Linux系统的编码问题 (2)xshell终端的编码问题 (3)两端的语言编码不一致 因此解决方法: (1)首先查看Ubuntu(Linux)编码是什么,用locale命令,并确保输出中包含:LANG=en_US.UTF-8,如果没有,则用命令export LANG=en_US.UTF-8将环境变量LANG设置成en_US.UTF-8。 (2)将xshell的编码设置的和Ubuntu一致。打开会话选择窗口,点击对应会话的右键菜单中的“属性”,在打开的“属性”窗口中:“终端”——“转换”——“编码”栏选择“Unicode(UTF-8)”即可。