Scrapy是开源免费的的Python爬虫框架,它包含了多种爬虫特性,可使用xpath、css、正则表达式等方式提取指定数据,并能将爬取到的数据保存到csv、json等多种格式的文件中。其开发简便,功能强大,适合很多爬虫应用。
一、Scrapy工程开发步骤
用Scrapy抓取网站可谓非常简单,共分为四个步骤:
1.创建Scrapy项目,以名为test的项目为例,在scrapy shell中输入:
$scrapy startproject test
则会创建如下目录结构:
test/
|---test/
| |---__init__.py
| |---items.py
| |---pipelines.py
| |---settings.py
| |---spiders/
| |---__init__.py
| ....
|---scrapy.cfg
2.定义存放爬取的内容数据的Item容器
爬虫爬取的数据被提取处理存放在item中,item与字典类似并提供额外保护机制来避免拼写错误导致的未定义字段错误。创建Scrapy项目时,会在项目目录下自动生成的文件items.py,这就是定义item字段的地方。例如,若要提取标题title和价格price字段,只需要在TestItem类中加入如下对应的字段定义即可:
import scrapy class TestItem(scrapy.Item): title = scrapy.Field() price = scrapy.Field()
3.编写爬虫程序
在项目的spiders目录下的创建爬虫文件,继承自scrapy.Spider类,并定义一下属性及方法:
name——用于区别不同爬虫。不同蜘蛛类中,名字必须是唯一的。
start_urls——包含爬虫启动时进行爬取的初始URL列表。因此,第一个被获取到的页面将在其中,而后续URL可以从被爬取的页面中提取。
allowed_domains——过滤爬取的域名,在插件OffsiteMiddleware启用的情况下(默认是启用的),不在此允许范围内的域名就会被过滤,而不会进行爬取。
parse()——爬虫爬取方法。当下载器返回响应页面时,该方法会被调用,因此该方法负责解析返回的响应数据,提取其中有用的信息生成item并生成需要进一步处理的URL的请求对象Request。start_urls列表中的每个URL页面下载后会生成Response对象,该对象会作为parse()方法的除self外的唯一参数。
简单实例如下:
import scrapy
from test.items import TestItem
from scrapy.selector import Selector
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, Join
class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['lianjia.com']
start_urls = ['https://cd.lianjia.com/ershoufang/106100978634.html']
def parse(self, response):
l = ItemLoader(item=TestItem(),response=response)
l.add_xpath ('title', '//div[@class="sellDetailHeader"]//div[@class="sub"]/text()', MapCompose(unicode.strip))
l.add_xpath ('price', '//div[@class="overview"]//div[@class="price"]/span/text()', MapCompose(lambda i:i.replace(',',''), float), re='[,.0-9]+')
return l.load_item()
4.存储爬去的内容
最简单的存储爬取数据的方式是使用Feed exports,主要可导出四种格式:Json、Json lines、CSV、XML。以导出Json格式的数据为例,在scrapy shell中运行:
$scrapy crawl basic -o items.json -t json
-o后面是导出的文件名,-t指定导出类型,执行该命令后根目录下会创建items.json文件,里面存放的是爬取的内容。
二、Scrapy框架的组成
下图是Scrapy框架的组件构成及相互间的交互情况:
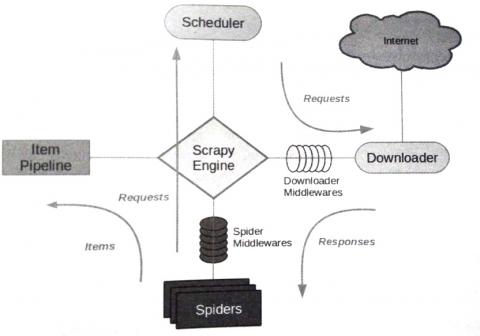
1.引擎——Scrapy Engine
引擎是爬虫工作的核心,负责控制数据流在系统中所有组件的流动,并在相应动作发生时触发对应的事件。
2.调度器——scheduler
从引擎接受页面请求,并将其入队,以供后续引擎处理。
3.下载器——Downloader
负责获取页面数据,并通过引擎最终提交给爬虫处理。
4.爬虫——spiders
用户编写的用于分析下载器返回的相应数据,提取出所需的信息,存放于item。还可包含额外跟进的URL类。
5.项目管道——Item pipeline
负责处理由爬虫提取的item,进行清理、验证及持久化(存储)等相关处理。
6.下载中间件——Downloader Middlewares
引擎与下载器间的特定钩子(specific hook),处理下载器传递给引擎的响应。
7.爬虫中间件——Spider middlewares
引擎与爬虫间的特定钩子(specific hook),处理蜘蛛程序的输入(来自下载器的响应)输出(提取的item交给项目管道,页面请求),
著作权归作者所有。商业转载请联系本站作者获得授权,非商业转载请注明出处 ZZKOOK。
评论
我真心分享
LZ实在太好了
楼主实在最棒