一、全局命令
1.启用scrapy shell
$ scrapy shell -s USER_AGENT="Mozilla/5.0" --pdb http://example.com
说明:
USER_AGENT:设置一个代理头,以便目标网站回应
--pdb:启用交互式调试,避免发生异常
2.创建scrapy项目
$scrapy startproject projectname
说明:
projectname:替换为项目名称
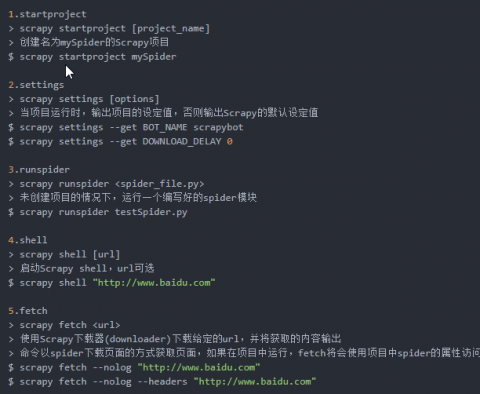
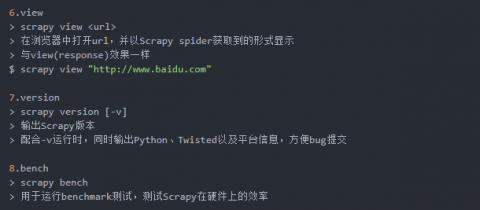
常用的还有:
二、项目命令
项目命令必须再scrapy创建的项目目录中运行,该目录包含文件scrapy.cfg.
1.为项目创建蜘蛛
$cd projectname
$scrapy genspider spidername web
说明:
spidername :替换为爬虫名称
2.运行爬虫程序
$scrapy crawl spidername
3.用指定爬虫爬取给定的任意URL
$scrapy parse --spider=spidername http://example.com/page2.html
4.将爬虫程序的结果输出到文件
1)输出为json
$scrapy crawl spidername -o items.json
2) 输出为csv
$scrapy crawl spidername -o items.csv
3)输出为xml
$scrapy crawl spidername -o items.xml
4)输出为json行文件(每行一个JSON对象,避免json文件中JSON对象过大引起的内存问题)
$scrapy crawl spidername -o items.jl
5)上传到FTP服务器
$scrapy crawl basic -o "ftp://user:password@192.168.211.1/items.json"
$scrapy crawl basic -o "ftp://user:password@ftp.example.com/items.json"
6)上传至S3存储桶
$scrapy crawl basic -o "s3://aws_key:aws_secret@scrapybook/items.json"
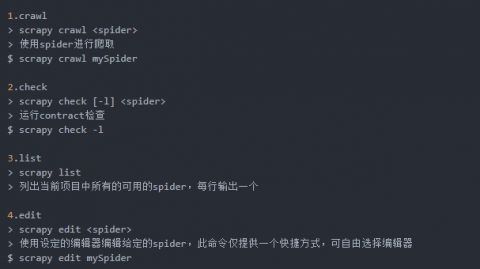
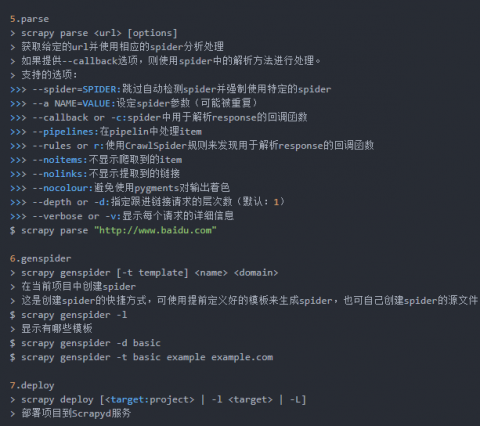
著作权归作者所有。商业转载请联系本站作者获得授权,非商业转载请注明出处 ZZKOOK。
评论
楼主实在最棒
本人不得不分享
楼主实在好人