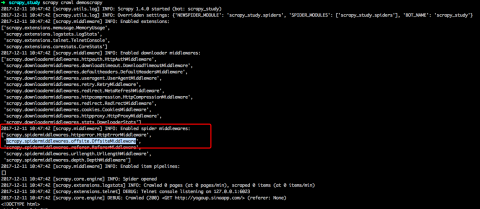
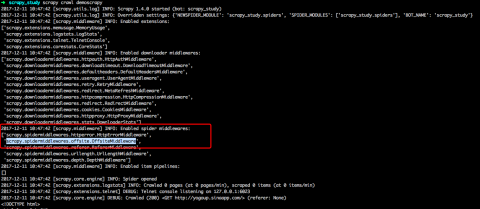
利用如下代码从多页爬取,但似乎Request没有调用,或其回调函数没有调用?
def parse(self, response):
#水平爬取
next_selector = response.xpath('//*[contains(@class, "house-lst-page-box")]//a[last()]/@href')
for url in next_selector.extract():
yield Request(urlparse.urljoin(response.url, url))
#垂直爬取
item_selector =response.xpath('//ul[@class="sellListContent"]/li/a/@href')
for url in item_selector.extract():
yield scrapy.Request(url, callback = self.parse_item)