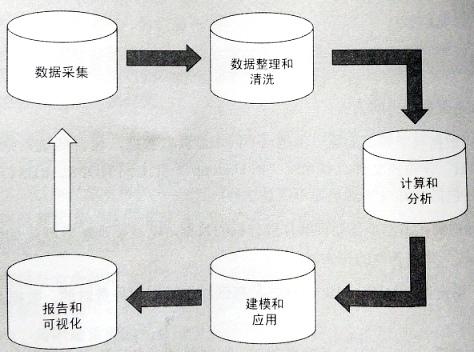
数据科学管道通常分为以下5个并非完全顺序的基本过程:
1.数据获取
从不同来源获取数据,包括:数据库、NoSQL文件、网页抓取信息、分布式文件存储系统(例如Hadoop平台上的HDFS、RESTful API、文本文件),甚至PDF等。
2.探索和理解
辅以探索,深入理解要分析的数据以及这些数据如何采集;通常数据探索会让数据清洗过程更清晰,清洗后的数据需要更多探索和更深理解。
3.改写、整合、处理
将获取来的数据进行清洗,转换成目标形式。该过程通常耗费数据分析项目80%的时间,例如:数据字典改变、丢失;数据域中存在垃圾;数据值域的重新定义;被抓取Web页面改版、升级导致的数据缺失。
4.分析、建模
从数据中得到变量之间的统计关系,并使用机器学习技能进行聚类、分类、预测等。
5.交流和实施
按指定的形式和结构交付结果,无论是给下一轮迭代还是发送给各种不同用户,结果可以是一次性报告,也可以是Web产品。这并非仅仅是数据的可视化,也并非仅仅做一些酷炫的图形了事。数据可视化是和数据分析在一起的。数据分析要讲述数据中分析的结果,辅助决策者的决策才有意义。
著作权归作者所有。商业转载请联系本站作者获得授权,非商业转载请注明出处 ZZKOOK。
评论
楼主真的最棒
博主真的太好了
LZ真的感谢分享
LZ真的谢谢你
博主实在最棒